INTRODUCTION
Salesforce's Force.com platform is an incredibly powerful solution for building enterprise web applications. However, using Force.com's native VisualForce pages is not aways an attractive solution for creating full-featured interfaces since you are required to host those pages within the Force.com platform.
Fortunately, nearly all of Force.com's capabilities are exposed through their extensive API, including custom objects and apex-code that is annotated as a web service. In this post, I will demonstrate how to use the Force.com RESTful APIs to build a simple web application using Google's new Dart language.
Dart represents the next generation in building enterprise calibre web applications. While similar in syntax to Java or C#, it still contains many of the most powerful features found in Javascript, such as its asynchronous programming model and treatment of functions as first-class objects. In many respects, it blends the most powerful features of Java and Javascript, while sprinkling in sugar such as integrated unit testing support; DOM-based query and manipulation features like jQuery provides; and, interestingly, can be written for both client and server-side applications (not unlike Javascript and node.js).
For those of you unfamiliar with Dart, it uses a similar model to Google's GWT. That is, the code you write for client-side browser applications is compiled into Javascript for run-time deployment. Dart's compilation process deals with the complexity of creating the proper native Javascript for each of the major browsers. In addition, Google provides a very nice Eclipse-based IDE for development, and a special version of Chrome called Dartium that enables Dart code to be run natively without the Javascript compilation process being required (very handy for rapid development). Because Dart is compiled into Javascript for deployment, it optimizes the Javascript code produced, so that only the exact code needed to run the application is actually getting generated (called "tree shaking" by the Dart folks).
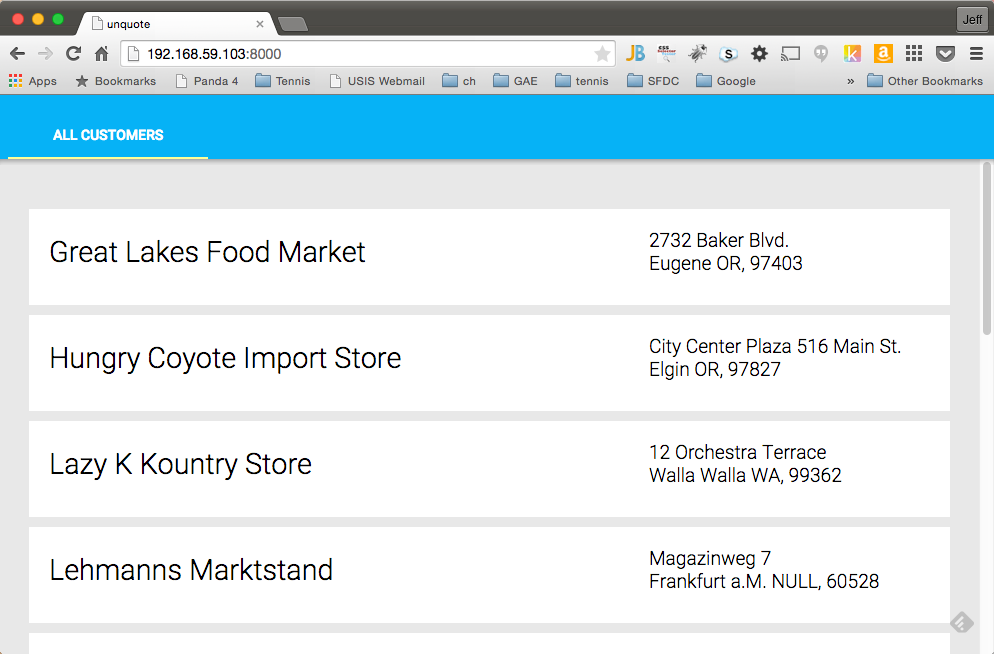
The application we'll be creating is really pretty simple -- it's a single webpage with tabs used for listing Salesforce Accounts and User objects. Here's an example of what it looks like:
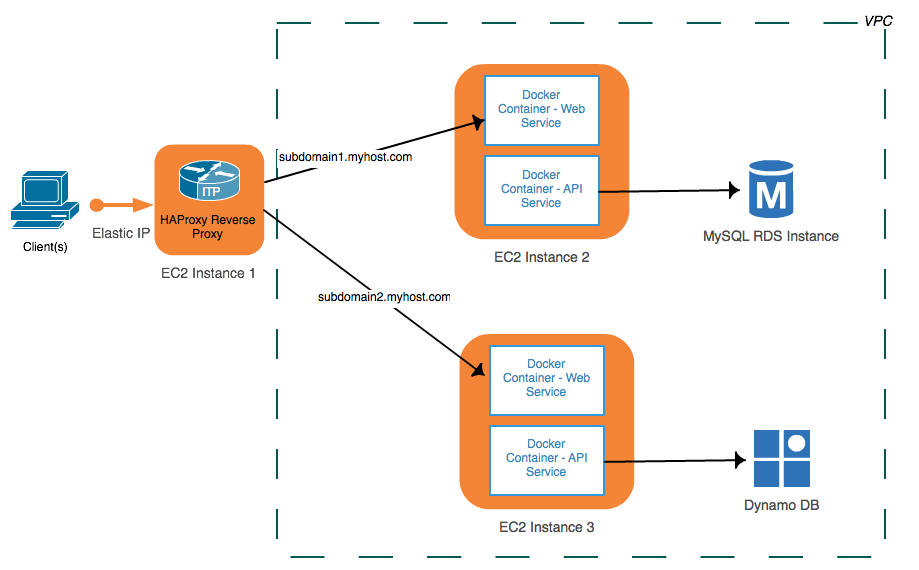
Since it's currently not possible to invoke the Salesforce API's directly within a web page unless hosting the page through the Force.com infrastructure (due to cross-domain Javascript restrictions), a server component (also written in Dart) is used to proxy the client requests to Salesforce. The graphic below is a high-level overview of the solution:
This sample project includes both the Dart server and client components.
In order to run this application, you'll need at least a
Force.com developers account (which is free), and Dart version 0.4.3.5 or greater (it may work on earlier versions as well, but I didn't test it). You can download the Dart SDK, IDE and Dartium at Dart's
website.
SETUP
For security reasons, your instance of Salesforce will need to be setup to allow outside RESTful API calls to be placed. The steps required are outlined in detail at
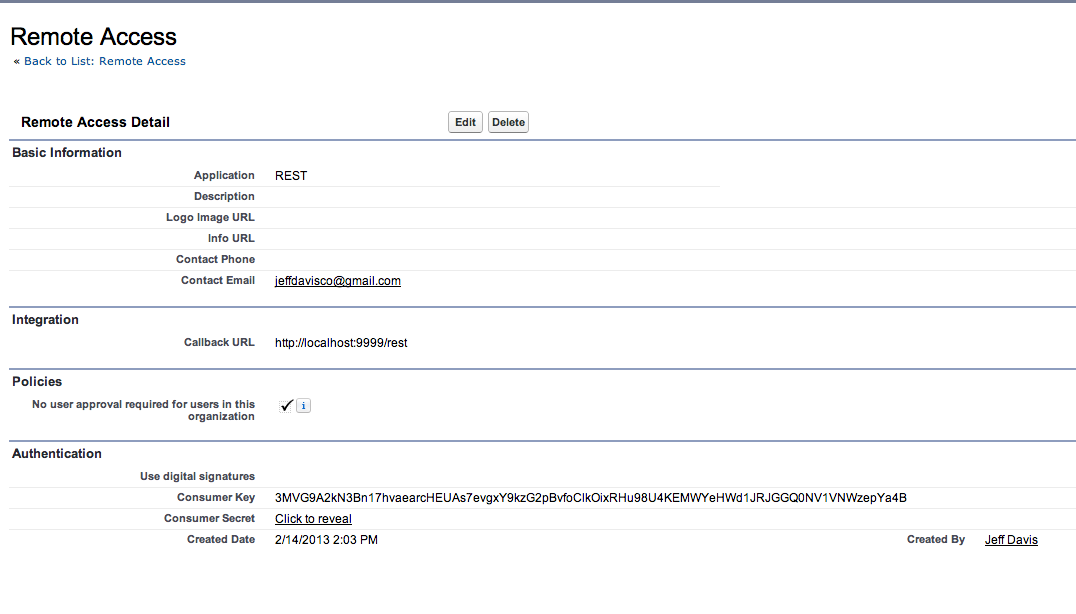
http://www.salesforce.com/us/developer/docs/api_rest/. However, if you are too impatient to follow that explanation (and many of the authentication steps described are only applicable for those using OAuth, which we're not using in this example), what you must do is configure your Salesforce instance for remote access. This is done via the
Setup->
Develop->
Remote Access configuration page, shown below:
After entering all of the required values, you will be provided a consumer key and consumer password, as shown above. When using the force.com API, you can authenticate using either OAuth or via the token/session id. We're using the later in this example.
LOGGING INTO SALESFORCE USING REST
Before we jump into the Dart code and samples, let's first examine how to use the Salesforce's API from the command line. Before we begin placing calls to access the the remote objects, a session or token must be first acquired. Below illustrates how this is done using curl from the command line (broken up into multiple lines for purposes of explanation):
curl -d "grant_type=password&
client_id=3[consumer-key]&
client_secret=[consumer-secret]&
username=[sfdc-login-email-address]&
password=[sfdc-login-password]"
In your case, you'll be replacing the values found within the [ ] with those appropriate to your environment. The [consumer-key] and [consumer-secret] are those values captured from the previous screenshot/form. The other two values represent the regular salesforce.com username and password used to login to salesforce, and similarly for the login URL (notice I'm using a sandbox instance of salesforce, hence it begins with test.).
After invoking the command, you should see a JSON response that resembles:
{
"id" : "https://test.salesforce.com/id/00DT6EAM/005i000AA",
"issued_at" : "1365989902442",
"instance_url" : "https://cs15.salesforce.com",
"signature" : "GVY9jxn/2Y+gAfewy6rq+l2DAqRza5A8U4g=",
"access_token" : "[not shown]"
}
The two values that are most relavent are the instance_url, which is the URL location where subsequent calls must be placed, and the access_token, which represent the session id that is also used on subsequent calls (the access_token will remain active for only a few hours after which a new one must be acquired).
Now that we have the required login credentials, we can place some API calls to retrieve back data from the Salesforce instance. For example, let's place a call to retrieve back some data from the Account object (NOTE: use single quotes around authorization header, as shown below following -H flag).
curl [instance_url]/services/data/v27.0/query?q=SELECT+id,name,type,description,industry+FROM+account+ORDER+BY+name -H 'Authorization: Bearer [access_token]'
In this example, a GET request is being issued that runs a SQL-type select statement against the Account object in Salesforce. In this case, I'm bringing back the type, description and industry properties from the Account table and ordering the results by the name property. Here's an example of the JSON that is returned:
{
"totalSize" : 2,
"done" : true,
"records" : [
{
"attributes" : {
"type" : "Account",
"url" : "/services/data/v27.0/sobjects/Account/001e00000GAMYAA4"
},
"Id" : "001e0000006GAMYAA4",
"Name" : "Acme Child Corporation",
"Type" : "Customer",
"Description" : "Acme Child is a child of Acme Parent.",
"Industry" : "Consulting"
},
{
"attributes" : {
"type" : "Account",
"url" : "/services/data/v27.0/sobjects/Account/001e0005prfhAAA"
},
"Id" : "001e0000005prfhAAA",
"Name" : "Acme Corporation Parent",
"Type" : "Customer",
"Description" : "Description",
"Industry" : "Insurance"
}
]
}
Now that you have a flavor of how the Salesforce API works, let's dig into Dart.
SERVER-SIDE DART
While you maybe getting pretty excited about the prospect of using the Salesforce API directly from within Javascript on the client, this unfortunately is not possible due to the restrictions found in Javascript when calling AJAX calls from a remote server (cross-domain scripting). Of course, you can build and deploy pages directly within the Force.com infrastructure (i.e., VisualForce pages), but this requires hosting your pages in their instance. While there are some work-arounds (
CORS), they remain a bit kludgy (although the Dart sample code for this project illustrates supporting CORS in the Dart server that is used).
To get around this issue for our example, we'll use server-side Dart as a proxy type service to remotely call the Salesforce API as well as serve up our web application. Using Dart on the server-side is very attractive, as it means that a single language can be used to both develop the backend and front-end portions of our application. This no doubt helps explain why node.js is becoming so popular -- it supports the ability to program server-side applications using Javascript.
While I really don't want to personally argue over the merits of using Javascript, I personally find the language less than ideal, especially coming from a Java background. Understanding how prototypes work as a replacement to classes/inheritance remains somewhat murky for me as, and its heavy use of asynchronous callbacks can create some rather unwieldy code. Dart, in my opinion, marries the best features of Javascript with those of Java. In particular, Dart likewise heavily relies on an asynchronous model, but it deals with its complexity by using a concept known as
Futures (granted, there are some similar implements with Javascript, but it's not native).
Let's examine how we can use Dart to proxy service calls to Salesforce. The first thing we must do is setup a Dart program that will act as a web server. This is accomplished using the Dart:io library. Since we also want to use the server to serve-up web pages and their artifacts (css files, images etc), we need to first instruct the server where to locate these files (setting up a Dart server is a pretty low-level exercise, as you'll see here -- there are some external packages that simplify these steps). This identification is done within the main() method of the server code found in the server.dart file (like Java, a Dart program is invoked through a main method):
main() {
// Compute base path for the request based on the
// location of the script and then start the server.
File script = new File(new Options().script);
script.directory().then((Directory d) {
startServer(d.path.substring(0,
d.path.lastIndexOf('bin')) + 'web/');
});
}
To be honest, I'm not 100% sure how the Options().script method identifies the local path/directory where the server is running from, but I didn't concern myself overly with such details, as this is a common use pattern. In this code, we witness our first use of a callback, which can be easily identified as in use via the shorthand then method. In this example, the code states that after the script method is invoked, we're provided a Directory object that we can use to acquire the path location where the server is running. In this case, the server code is running in the bin subdirectory, but I've split apart my web application artifacts into another directory at the same level as bin called web, which I'm simply replacing for bin via the substring method.
Now that I have the location where my web artifacts reside (web), I can then run the method that will actually start the server. Appropriately enough, it's in the startServer method, to which I'm passing the directory path we acquired. Let's take a look at the startServer method:
startServer(String basePath) {
HttpServer.bind('127.0.0.1', 9090).then((server) {
print('Server started, Port 9090');
print('Basepath for content is: ' + basePath);
server.listen((HttpRequest request) {
print("Received " + request.method + " request,
url is: " + request.uri.path);
switch (request.method) {
case "GET":
if (request.uri.path.contains('api'))
handleApi(request, basePath);
else
handleGet(request, basePath);
break;
case "POST":
//handlePost(request); not yet implemented
break;
case "OPTIONS":
handleOptions(request);
break;
}
});
});
}
As you can likely discern, the HttpServer.bind static method is used to initiate the web server under localhost port 9090. Once binded, an HttpServer object is assigned to the variable server, and in turn, it begins listening for inbound connections. Once an inbound connection is received, it is routed to other methods for processing based upon a) the inbound connection's HTTP method (i.e., GET, POST etc) and b) in the case of a GET, it is further routed based upon whether the request URL contains "api" or not.
Before we examine the handleApi method, which is where we invoke the various Salesforce API calls, let's first explore how we can call a RESTful API using Dart's IO library (the io library, by the way, can only be used server-side with Dart, since it includes calls to the local filesystem etc).
PLACING RESTFUL CALLS WITH DART's IO LIBRARY
In this project, we're returning back a list of Accounts and Users from Salesforce.com. Eventually we'll display those lists within a web page. For each of these two object types, I created a separate class that contains both the logic required to place the API call as well some unit tests. Let's look at the Dart Account class (found in bin/classes/account.dart file):
class Account {
static Future getAllAccounts(String sessionId, String host) {
Completer accntResponse = new Completer();
Future reply =
SFDCUtils.getRequest('${host}${Constants.QUERY}${Constants.QUERY_ACCOUNT_ALL}',
sessionId);
reply.then( (JsonObject response) {
accntResponse.complete(response);
});
return accntResponse.future;
}
}
The first thing to note is that the getAllAccounts method returns a Future object of type JsonObject. What this means is that this method represents an asynchronous call, and when the method is completed, it will notify the calling code accordingly. In other words, it represents a promise that a value will eventually be returned, when processing is completed. Since we are calling an external service, this is sensible approach. However, this code doesn't provide any real insight into how the Salesforce API is invoked, as this logic takes place within the SFDCUtils.getRequest static method. Let's take a look at that code:
static Future getRequest(String url, String sessionId,
[String contentType = Constants.CT_JSON]) {
HttpClient client = new HttpClient();
Completer respBody = new Completer();
var requestUri = new Uri.fromString(url);
var conn = client.getUrl(requestUri);
conn.then ((HttpClientRequest request) {
request.headers.add(HttpHeaders.CONTENT_TYPE, contentType);
request.headers.add('Authorization', 'Bearer ${sessionId}');
request.close();
request.response.then( (response) {
IOUtil.readAsString(response, onError: null).then((body) {
respBody.complete(new JsonObject.fromJsonString(body));
client.close();
});
});
});
return respBody.future;
}
This could be considered a "helper" method that can be used for any of the GET requests to Salesforce (a similar helper is provided for POST requests, but not covered here). The first thing that we do is to get an instance of Dart:IO's
HttpClient. We then follow it by creating an
HttpClientRequest object invoking the
getUrl method on the client object. With that, we can then setup the required HTTP header used for the Salesforce authentication (we'll see in a bit how the sessionId is first acquired) as well as for specifying the content type (unless provided as an optional parameter to the method, it's set to "application/json"). Lastly, we then invoke the HTTP request asynchronously and wait until the response is received. Once received, an external library is used (
IOUtil) to convert the response
Stream into a
String, represented by the
body variable. Lastly, we close the
HttpClientRequest using its
close method.
So, to circle back to the
Account class'
getAllAccounts method, once the helper has returned the JSON results from the HTTP, it indicates processing is completed by invoking the
complete method on the
Future response object.
One thing I haven't discussed yet is the use of the
JsonObject. When the response JSON is returned from Salesforce, it is converted to this
JsonObject (note -- this functionality is provided via a third-party utility). This object represents a map of the returned JSON, and allows for convenient dot-notation access to the JSON values. We can see this at play first-hand in the accompanying unit test for
Account, which we'll discuss next.
UNIT TESTING WITH DART
One of the nicest features of Dart is its built-in support for unit testing (for a more detailed understanding, see this
article). The
account.dart file, in addition to defining the class and methods for the
Account, also contains a
main() method that can be invoked to run one or more unit tests. Below is a unit test to exercise the
getAllAccounts method:
test('Account', () {
Future url = Credential.getCredentials();
url.then((JsonObject obj) {
String tokenId = obj.access_token;
String host = obj.instance_url;
Future accnts = Account.getAllAccounts(tokenId, host);
accnts.then((JsonObject jsonObj) {
expect(jsonObj.totalSize > 0, true);
});
});
});
As you can see, the first thing we do is to use the
Credential class'
getCredentials static method to return the credentials used to login to Salesforce (the
Credential class is very similar to
Account, so I don't bother covering it here). Once the
instance_url and
access_token are returned by the
getCredentials call, we use those as parameters to invoke the
getAllAccounts method. As you may recall, the JSON returned from the Salesforce API contains a
totalSize property that identifies how many records are returned. We use Dart's
expect method in a similar fashion to jUnit's
assert to determine whether the test was successful or not. When running in the Dart IDE, you'll see something like this in the console window indicating the test successfully passed.
unittest-suite-wait-for-done
request url is: https://test.salesforce.com//services/oauth2/token
PASS: Account
All 1 tests passed.
unittest-suite-success
Now that we've seen how the Salesforce API is invoked and the corresponding data returned, let's tie that into the server to see how the proxy functionality works.
IMPLEMENTING PROXY FUNCTIONALITY IN DART SERVER
If you recall, when a GET HTTP request is issued to the Dart server (found in the file
server.dart), if the URL of that request contains "api", the
handleApi method is invoked. Let's now examine this method to see how the proxy functionality is implemented:
handleApi (HttpRequest request, String basePath) {
HttpResponse res = request.response;
addCorsHeaders(request, res);
_getSessionId().then((Map credentials) {
sfdcCredentials = credentials;
switch (request.uri.path) {
case '/api/accounts':
Future accnts =
Account.getAllAccounts(sfdcCredentials['access_token'],
sfdcCredentials['instance_url']);
accnts.then((JsonObject jsonObj) {
res.write(jsonObj.toString());
res.close();
});
break;
case '/api/users':
Future orders =
User.getAllUsers(sfdcCredentials['access_token'],
sfdcCredentials['instance_url']);
orders.then((JsonObject jsonObj) {
res.write(jsonObj.toString());
res.close();
});
break;
}
});
}
As you can see, it's pretty straightforward. The HttpRequest object's uri path (URL) is extracted and then used as the basis for the switch statement that follows. If, for example, the inbound GET URL contains the prefix of "/api/accounts", then a list of of Account objects is returned wrapped within a JsonObject map. The results are then returned to the calling client as a JSON string. We follow an identical approach with the "/api/users" call. Most of the real work was offloaded to the individual Dart classes such as Account.
NOTE: CORS supported was added to the server (see the method addCorsHeaders)
, so cross-domain Javascript support is available. To read more on how it's implemented with Dart, see this article.
Now that we've got the proxy server completed, we can dive into how the UI is developed within Dart.
CLIENT-SIDE DART
The initial screenshot provided at the start of this article depicted the UI we'll be creating. As a quick refresher, it's just a web page with two tabs -- one to display a list of Salesforce Accounts, and the other tab Users. Let's begin by looking at a snippet of the HTML used to construct the page (sfdcdemo.html):
The design for the page uses
Twitter Bootstrap for the CSS layout, and the new Dart UI Widgets
library, which mirrors the Javascript functionality provided in Twitter Bootstrap, for the widget support. In this example, we're using the tab widget, which is implemented by way of the custom HTML Dart tag introduced called
<x-tabs>(for more information on creating custom Dart tags, see this article). As we will see in a moment, the Dart client code interacts with the above HTML by way of the id values assigned to some of the HTML elements. For example, when the list of Accounts is populated by Dart, it simply appends the tabular data to the table identified by the element id named accounttable. In this fashion, Dart's query method works similarly to jQuery.
Let's take a look at the fragment of Dart client code that corresponds to this HTML (sfdcdemo.dart) that is used for populating the Accounts tab.
When the page is first opened, the main method in sfdcdemo.dart invokes the populateAccountsTable method shown above. The first thing that is done is to invoke an Ajax request to the server API proxy method we described previously (obviously, in a production type environment, the host wouldn't be hard-coded as above). Once the results of the call are returned, a JsonObject is populated with the data, and then we simply iterate through the results to dynamically construct the HTML table body. Once the HTML is constructed, we use Dart's query mechanism to locate the target element id in the DOM, and then append the new dynamic HTML results. Couldn't be much easier!
The
sfdcdemo.dart file also contains a method called
populateUsersTable, and it's used to populate the User tab in the HTML. It follows an identical pattern as
populateAccountsTable.
The easiest way to run this project is to a) open the project in the Dart IDE and b) right-click on the
sfdcdemo.html file and select "Run in Dartium". Of course, you will first need to follow the steps outline in the pre-requisites and setup sections.
In a future posting, I hope to replace the existing HttpClient mechanism on the Dart client for placing the AJAX calls to populate the tabular data with web sockets.